
「RAGを導入したいけれど、どんなデータベースを選べばいいのかわからない…」「検索精度を上げるには、どんな最適化が必要?」そんな疑問を抱えるエンジニアの方に向けて、RAGデータベースの構築と最適化のポイントを解説します。
この記事では、RAGによる生成AIの精度向上を目指す際のデータベース選定と最適化手法を、できるだけわかりやすく紹介します。ただし、実際の運用では検索アルゴリズムやデータの品質、モデルやドメインの特性によって結果が変わるため、適宜検証や調整が必要です。
【この記事で学べること(最適化手法4選)】
- RAGに適したデータベースの選び方
- データの前処理と正規化の最適化
- インデックスと検索アルゴリズムの最適化
- データ更新とリアルタイム検索の仕組み
適切なデータベースを構築し、検索精度を高めることで、RAGを最大限に活用した生成AIを目指せます。ここで紹介する内容を踏まえつつ、エンジニアとしてさらなる検証や運用上の工夫を行い、プロジェクトの成功につなげてください。
RAGとは?生成AIとの関係とデータベースの重要性

本記事では、RAG(Retrieval-Augmented Generation)の基本概念からデータベースの重要性、そしてベクトル検索の仕組みまでを解説します。RAGは生成AIの精度や信頼性を高めるうえで注目されるアーキテクチャですが、導入にあたってはモデルの制約やデータの管理方法にも配慮が必要です。
RAG(Retrieval-Augmented Generation)とは?
RAGは、外部データベースと生成AIを組み合わせることで、より正確かつ信頼性の高い回答を目指す技術アーキテクチャです。一般的な大規模言語モデル(LLM)は、学習後に新規情報を直接取り込むことが難しい傾向があります(継続的な学習やファインチューニング等で対応する方法は存在しますが、即時に最新情報を反映するには工夫が必要です)。RAGでは、これらのモデルの弱点を外部データベースとの連携で補い、より実用的な回答を生成しやすくします。
- 医療分野の例: 最新の研究論文や治療ガイドラインをデータベースに登録すれば、RAGがそれらの情報を参照しながら応答を生成できます。ただし、データの質や検索アルゴリズムの精度によって回答の正確性が左右される点には注意が必要です。
生成AIの制約を補う技術
RAGは、生成AIが自身で学習した情報以上のデータを参照できるようにすることで、回答内容を補強する仕組みです。医療や法務、金融など、情報の正確性が重視される領域では特に注目されていますが、RAGを導入しただけで必ずしも「常に正しい回答」が得られるとは限りません。データの管理・検証や適切な検索方式の採用が成功の鍵となります。
なぜRAGにはデータベースが必要なのか?

生成AIの制約とデータベースの役割
従来の生成AI(大規模言語モデル等)は、学習時点までのデータを元に予測を行います。ファインチューニングやプロンプト工夫によって新情報を反映できる場合もありますが、都度の再学習にはコストや時間がかかることが多いです。一方で、RAGでは外部データベースを組み込むことで、最新情報へのアクセスや組織固有の知識活用が可能になります。
- 企業の製品マニュアル登録: 最新版のマニュアルを登録し、検索精度を高めれば、より正確でビジネス要件に合った回答を生成しやすくなります。もちろん、情報の更新頻度や構造化の度合いが高いほど、検索と生成の両面でメリットが大きくなるでしょう。
データベースとRAGの連携イメージ
- 質問を受け取る
- データベースからベクトル検索などで関連情報を取り出す
- 取り出した情報を基に生成AIが回答を作成する
このプロセスにより、生成AI単体では補いきれないドメイン知識や最新情報を参照できます。ただし、検索アルゴリズムや埋め込み(Embedding)の品質によって参照情報の適切さが大きく変わるため、実装や運用における注意点も多いです。
RAGを支えるベクトル検索の仕組み

ベクトル検索とは?
テキストや画像といったデータを数値ベクトルに変換し、類似度計算を行うことで検索を行う手法です。キーワード検索よりも意味的な近さを重視し、「自動車の燃費」と「車の省エネ性能」のように表現は異なるが意味が近い文脈を扱いやすくなります。
RAGとの組み合わせで得られるメリット
RAGで回答を作成する前に、ベクトル検索によってより関連度の高い情報を取得できれば、回答の信頼性が向上する可能性があります。しかし、検索結果の品質はベクトル化モデルや検索パラメータに左右されるので、実装後の検証・チューニングが不可欠です。
RAGに適したデータベースの選び方【主要3選】
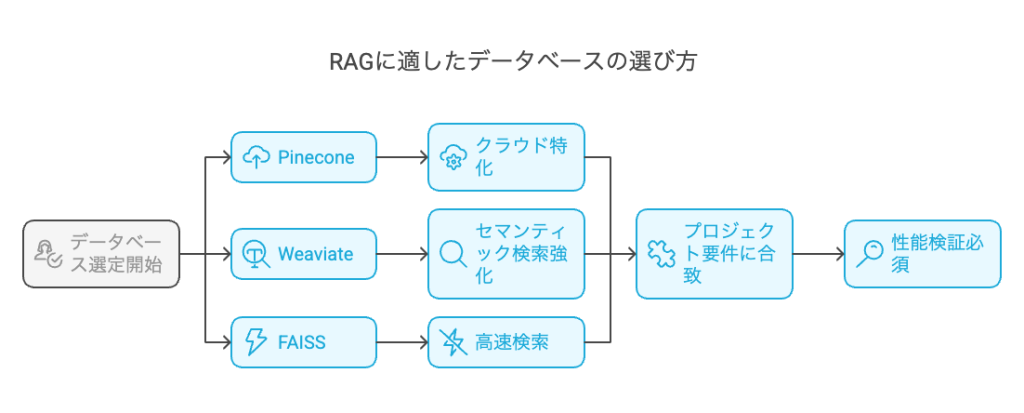
RAGシステムを構築する際、プロジェクト要件に合ったデータベースを選ぶことは重要です。ここでは、代表的なベクトルデータベースを3つ紹介します。例示する運用事例や性能指標はあくまで一般的な傾向であり、実際の性能はシステム環境やデータ規模に大きく依存します。
1. Pinecone:スケーラビリティに優れたクラウド型
- 特徴: 高性能なクラウドネイティブベクトルデータベースで、インフラ管理をPinecone側が担う
- メリット: 運用負荷が低く、ビジネスの成長に合わせて柔軟にスケール可能
- 活用例: Eコマースサイトの商品検索などでよく挙げられる。
- 数百万件レベルのデータを扱うことも可能とされるが、具体的な応答速度やベンチマークはシステム構成・リソースに左右されるため、Pineconeの公式ドキュメントやユーザー事例を参照して検証が必須。
2. Weaviate:セマンティック検索に強いオープンソース
- 特徴: キーワード検索とセマンティック検索を組み合わせたハイブリッド検索が可能
- メリット: 複雑なデータ構造や意味的関係を考慮しやすい
- 活用例: 法律文書検索等での利用が見込まれているが、法務ドメイン特有の専門用語や文体に合わせた埋め込みモデルや前処理が必要。実際の「高精度」を実現するには、追加の調整や学習が不可欠。
3. FAISS:高速なオンプレミス向けライブラリ
- 特徴: Meta社(旧Facebook)が開発した高性能ベクトル検索ライブラリ。GPUの並列処理により高速化
- メリット: 大規模データセットでも高速検索が可能と言われる
- 活用例: 機密データを含む医療分野や金融分野でオンプレ運用するケースなどが考えられる
- 「数ミリ秒」の応答を謳う事例もあるが、実際にはGPUの種類やデータ規模、インデックス構造によって速度が大きく変動する点に留意が必要。
| データベース | 特徴 | 適用例 | 運用形態 |
|---|---|---|---|
| Pinecone | クラウドネイティブで運用負荷低 | Eコマース検索 | クラウド専用 |
| Weaviate | セマンティック検索に特化 | 法律文書検索 | オープンソース(クラウド/オンプレ) |
| FAISS | GPU対応で大規模データを高速検索可能 | 機密データの高速処理 | オンプレ/ローカル |
RAGデータベースの構築手順【初心者向け解説】

ここでは、実際にRAGシステムを構築する際の一般的な流れを紹介します。ただし、プロジェクト特有の要件に合わせて手順やツール選定をカスタマイズすることが必要です。
1. データの収集と前処理
RAGシステムでは、もととなるデータの品質が検索精度や回答の正確性を大きく左右します。以下の点に留意しながら、クリーンなデータセットを整備しましょう。
- 古い情報や重複内容の削除
- ファイル形式の統一(PDFやWord、テキストなどを必要に応じて変換)
- 専門用語や略語の展開
- 曖昧表現の整理
医療分野の場合、用語の正規化やバージョン管理(古い治療ガイドラインを混在させない)が特に重要です。また、検証データ(テストセット)を別途用意して、前処理の効果を確認することもおすすめします。
2. ベクトル化(Embeddings)によるデータ変換
テキストデータを数値ベクトルへ変換し、意味的な類似度検索を可能にします。
- オープンソースモデル(BERT系、Sentence Transformersなど)
- 有料API(OpenAIなど)
例えば、「自動車の性能」に関するクエリを出したときに、「車の燃費」「省エネ性能」のような記述も同一文脈と判断されやすくなります。ただし、ドメイン(医療・法律など)に特化したモデルでなければ適切に類似度を捉えられないケースもあるので、ドメイン適合性の検証が必要です。
3. インデックスの作成と検索性能の向上
ベクトルデータを高速かつ正確に検索するために、適切なインデックス構造を選択・構築します。
- 例1: Eコマースでは商品名、カテゴリ、説明文などで複合インデックスを検討
- 例2: 法律文書では条文の階層構造に合わせた索引設計を行い、セマンティック検索と組み合わせる
大規模データセットほどインデックスの設計やハードウェアのスペックが検索速度に大きく影響します。開発段階で負荷試験を行い、応答速度や精度を検証して最適化しましょう。
検索精度を向上させるRAGデータベースの最適化手法

ここでは、RAGデータベースの検索精度と回答品質を高めるために有効とされる4つの手法を解説します。実際の導入では、検証データを用いたABテストやユーザー評価を取り入れながら調整していくことが大切です。
【手法1】適切なデータベースの選定
- 例: スケーラビリティ重視 → Pinecone
- 例: セマンティック検索重視 → Weaviate
- 例: オンプレ高速検索 → FAISS
どのデータベースでも、公式ドキュメントやユーザー事例での実測値を参考にし、自社の要件(検索速度、セキュリティ、コストなど)に合致するかを検証しましょう。
【手法2】データの前処理と正規化
- ノイズの徹底排除、専門用語や略語の統一
- 医療・法律などの特化ドメインでは、用語辞書やガイドラインを整備
データ品質が低ければ、いくら高度なデータベースやモデルを使っても回答精度に限界があります。**データ管理の仕組み(更新頻度やレビュー体制)**も同時に整備すると効果的です。
【手法3】インデックスと検索アルゴリズムの最適化
- ベクトル検索アルゴリズムのパラメータ調整(例: HNSW、IVF-PQなど)
- キーワード検索とベクトル検索を組み合わせたハイブリッド検索
大規模データの場合、インデックス構築に時間やリソースを要しますが、定期的な再構築とチューニングで検索速度を維持しつつ精度を高められます。
【手法4】データ更新とリアルタイム検索の仕組み
- 情報が頻繁に更新されるサイト向けには、増分更新やインメモリキャッシュを活用
- ユーザーに最新情報を提供するため、更新履歴の管理やバックエンドの自動化も検討
例えばニュースサイトやSNSの投稿を扱う場合は、古いデータとの混在による回答の誤差にも注意が必要です。
RAGデータベース導入時に押さえるべきポイントと注意点

RAGをビジネスで活用するためには、技術面だけでなく、コストやセキュリティ要件といったビジネス上の課題も重要です。
1. RAGの精度を最大化するデータ管理のベストプラクティス
- 定期的なデータ品質チェック(古い情報の除去など)
- 更新履歴の管理とバージョンコントロール
- 重複データ・類似文書の整理
製造業の顧客サポートで回答精度が大幅に向上したという事例もありますが、どの程度向上したか(例: 50%改善など)は企業独自の評価指標と測定条件が絡むため、実際に導入する際には自社データでの検証が必要です。
2. 検索性能を維持するための運用戦略
- システムのモニタリング、インデックスの定期再構築
- 負荷分散とスケールアップの計画
- ピークアクセス時の応答速度目標(例: 1秒以内)を設定し、負荷試験で検証
EコマースやWebサービスではアクセスが集中する時間帯を想定し、インフラをどのようにスケールさせるかが重要な検討事項となります。
3. ビジネス活用時に生じる主な課題
- コスト最適化: クラウド利用に伴うランニングコスト、オンプレ設備投資
- パフォーマンス要件: 応答速度・同時接続数の見積りと実測
- セキュリティ・コンプライアンス: 金融機関や医療機関など規制の厳しい領域での導入事例は存在するものの、具体的なハイブリッド運用やセキュリティ要件のクリア方法は事例ごとに異なるため、詳細な調査が必要
たとえば金融業界では、オンプレ環境とクラウドを併用するハイブリッド運用でリアルタイム性とセキュリティを両立させる例があるとされますが、セキュリティ認証(PCI DSSなど)への適合やデータ保護のプロセスを事前に十分検証する必要があります。
まとめ:最適なRAGデータベースを構築し、AIの精度を高めよう
RAGシステムの性能を引き出すには、適切なデータベース選定と4つの最適化手法の実践が欠かせません。
- プロジェクト要件に合ったデータベースを選ぶ
- Pinecone、Weaviate、FAISSなどから、規模・セキュリティ・検索需要に合わせて選択
- データの前処理と正規化を徹底する
- 古い情報や重複データの整理、専門用語や略語の展開などでデータ品質を向上
- インデックスと検索アルゴリズムを最適化する
- ベクトル検索の利点を活かし、大規模データでも高速かつ高精度を追求
- データ更新とリアルタイム検索を整備する
- 常に最新情報を提供できる仕組みを作り、ユーザー満足度と信頼性を高める
さらに、導入後もデータ量や利用状況に応じて検証と最適化を繰り返す運用体制が重要です。特に医療や法律などの専門性が高い分野では、外部データベースの情報管理やセキュリティ、更新フローの整備が成否を分けます。記事で紹介した内容を参考に、自社やプロジェクトの要件に即したRAGデータベースを構築し、より高いAIパフォーマンスを実現してみてください。
本記事で紹介した手法や事例は一部を一般化したものであり、実際の運用結果や導入効果は組織や利用環境、データセットによって異なります。導入の際は必ず実証実験や小規模テストを行い、最適な形を模索していくことが望ましいです。